
Retrieving data from Splunk Dashboard Panels via API. Fist of all, why might someone want to get data from the panels of a dashboard in Splunk? Why it might be useful? Well, if the script can process everything that human analyst sees on a Splunk dashboard, all the automation comes very natural. You just figure out what routine operations the analyst usually does using the dashboard and repeat his actions in the script as is. It may be the anomaly detection, remediation task creation, reaction on various events, whatever. It really opens endless possibilities without alerts, reports and all this stuff. I’m very excited about this. 🙂
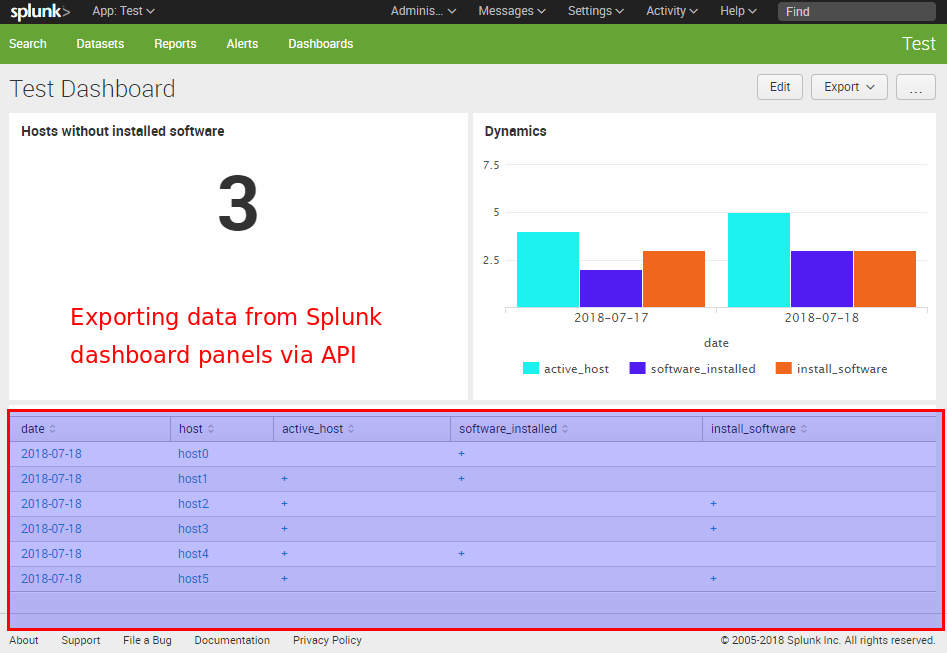
Let’s say we have a Splunk dashboard and want to get data from the table panel using a python script. The problem is that the content of the table that we see is not actually stored anywhere. In fact it is the results of some search query, from the XML representation of the dashboard, executed by Splunk web GUI. To get this data we should execute the same search request.
That’s why we should:
- Get XML code of the dashboard
- Get the search query for each panel
- Process searches based on other searches and get complete search query for each panel
- Launch the search request and get the results
First of all, we need to create a special account that will be used for getting data from Splunk. In Web GUI “Access controls -> Users”.
user = "splunk_user"
password = "password123"Getting XML code of the dashboard
Dashboard URL it already contains the name of application and the name of dashboard:
https://[server]:8000/en-US/app/important_aplication/important_dashboard
app_name = "important_aplication"
dashboard_name = "important_dashboard"We need to get app_author:
import requests
import json
splunk_server = "https://splunk.corporation.com:8089"
app_author = ""
data = {'output_mode': 'json'}
response = requests.get( splunk_server + '/services/apps/local?count=-1', data=data,
auth=(user, password), verify=False)
for entry in json.loads(response.text)['entry']:
if entry['name'] == app_name:
app_author = entry['author']
print(app_author)Output:
nobodyWhen we have app_author, app_name and dashboard_name we can get dashboard XML:
data = {'output_mode': 'json'}
response = requests.get( splunk_server + '/servicesNS/' + app_author + '/' + app_name + '/data/ui/views/' + dashboard_name, data=data,
auth=(user, password), verify=False)
dashboard_xml = json.loads(response.text)['entry'][0]['content']['eai:data']Getting the search query for each panel
We will parse XML code of this dashboard with Beautiful soup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(dashboard_xml, 'xml')
panels = list()
for panel in soup.find_all('panel'):
panel_dict = dict()
if type(panel.title) != type(None):
panel_dict['title'] = panel.title.text
else:
panel_dict['title'] = 'unnamed'
if type(panel.query) != type(None):
panel_dict['query'] = panel.query.text
else:
panel_dict['query'] = 'empty'
if type(panel.search) != type(None):
if 'id' in panel.search.attrs:
panel_dict['search_id'] = panel.search['id']
else:
panel_dict['search_id'] = False
if 'base' in panel.search.attrs:
panel_dict['search_base'] = panel.search['base']
else:
panel_dict['search_base'] = False
else:
panel_dict['search_id'] = False
panel_dict['search_base'] = False
if type(panel.earliest) != type(None):
panel_dict['search_earliest'] = panel.earliest.text
else:
panel_dict['search_earliest'] = False
if type(panel.latest) != type(None):
panel_dict['search_latest'] = panel.latest.text
else:
panel_dict['search_latest'] = False
panels.append(panel_dict)Output:
[{'query': u'eventstats max(date) as maxdate | where date == maxdate | fields - maxdate | fields ImportantField', 'search_base': u'first_search_id', 'search_id': False, 'title': u'Important Title'},...]Combining based search queries in complete search queries
Now we should get rid of connected searches. This part is a bit tricky. For each panel I recursively get the chain of based search IDs and combine related search queries. I also edit “complete” search queries to make them start with search command, which can be dropped in dashboard XML, but is mandatory in API requests, or “|” (I assume the case “| loadjob savedsearch…”)
import re
def get_search_id_list(search_base, panels):
search_id_list = list()
def get_base(search_base, panels):
for panel in panels:
if panel['search_id'] == search_base:
search_id_list.append(panel['search_id'])
if panel['search_base']:
get_base(panel['search_base'], panels)
get_base(search_base, panels)
reversed_search_id_list = list()
for title in reversed(search_id_list):
reversed_search_id_list.append(title)
return(reversed_search_id_list)
def get_panel_by_search_id(search_id, panels):
for panel in panels:
if panel['search_id'] == search_id:
return(panel)
def get_query_from_panel(panel):
query = panel['query']
if panel['search_earliest']:
query = "earliest=" + panel['search_earliest'] + " " + query
if panel['search_latest']:
query = "latest=" + panel['search_latest'] + " " + query
return query
dashboard_searches = dict()
for panel in panels:
query = ""
if panel['search_base']:
search_id_list = get_search_id_list(panel['search_base'], panels)
for search_id in search_id_list:
previos_panel = get_panel_by_search_id(search_id, panels)
query += " | " + get_query_from_panel(previos_panel)
query += " | " + get_query_from_panel(panel)
query = re.sub("^ \| ","",query)
query = re.sub("[ \t]*\|[ \t]*\|[ \t]*", " | ", query)
if not re.findall("^[ \t]*search",query) and not re.findall("[ \t]*^\|",query):
query = "search " + query
if panel['title'] in dashboard_searches:
n = 1
while panel['title'] + "_" + str(n) in dashboard_searches:
n += 1
panel['title'] = panel['title'] + "_" + str(n)
dashboard_searches[panel['title']] = queryWe get the dictionary, where title of the panel is the key and search query is the value.
Making a search request
The final thing is to make the search request and get the results. You can do it like this:
import time
dashboard = "Important Panel Title"
query = dashboard_searches[dashboard]
data = {'search': query, 'output_mode': 'json', 'max_count':'10000000'}
response = requests.post(splunk_server + '/services/search/jobs', data=data,
auth=(user, password), verify=False)
job_id = json.loads(response.text)['sid']
dispatchState = "UNKNOWN"
while dispatchState!="DONE" and dispatchState!="FAILED":
data = {'search': query, 'output_mode': 'json', 'max_count':'10000000'}
response = requests.post(splunk_server + '/services/search/jobs/' + job_id, data=data,
auth=(user, password), verify=False)
dispatchState = json.loads(response.text)['entry'][0]['content']['dispatchState']
time.sleep(1)
print(dispatchState)
if dispatchState=="DONE":
results_complete = False
offset = 0
results = list()
while not results_complete:
data = {'output_mode': 'json'}
response = requests.get(splunk_server + '/services/search/jobs/' + job_id +
'/results?count=50000&offset='+str(offset),
data=data, auth=(user, password), verify=False)
response = json.loads(response.text)
results += response['results']
if len(response['results']) == 0: #This means that we got all of the results
results_complete = True
else:
offset += 50000
print(results)Output:
[{u'data': u'value1'}, {u'data': u'value2'},...]The content of the table will be returned as a list of dictionaries, where name of the column is the key and cell value is the value in dictionary.

Hi! My name is Alexander and I am a Vulnerability Management specialist. You can read more about me here. Currently, the best way to follow me is my Telegram channel @avleonovcom. I update it more often than this site. If you haven’t used Telegram yet, give it a try. It’s great. You can discuss my posts or ask questions at @avleonovchat.
А всех русскоязычных я приглашаю в ещё один телеграмм канал @avleonovrus, первым делом теперь пишу туда.
Great article! Would wish there was something to extract data in a sensible fashion from OpenVAS (the CSVs sck).
OpenVAS + GSA + Splunk + DBConnect = reports as events
Pingback: How to list, create, update and delete Grafana dashboards via API | Alexander V. Leonov
I am getting dispatchState as Failed hence not able to get the data. Not able to figure out why its giving dispatchState as Failed. Any idea ?
Great article! But how we can take results of searches that use tokens in query?
Hi Aleksandr! Sorry, I haven’t tried to do this.
hey Alexander! thanks for the post. When attempting to get XML code of the dashboard, I am getting:
nobody
{
“messages”: [
{
“type”: “ERROR”,
“text”: “Could not find object id=DASHBOAD_NAME”
}
]
}
ever faced this? thanks.