Hello everyone! In this episode, I want to talk about vulnerabilities, news and hype. The easiest way to get timely information on the most important vulnerabilities is to just read the news regularly, right? Well, I will try to reflect on this using two examples from last week.
I have a security news telegram channel https://t.me/avleonovnews that is automatically updated by a script using many RSS feeds. And the script even highlights the news associated with vulnerabilities, exploits and attacks.
I have been a Splunk guy for quite some time, 4 years or so. I have made several blog posts describing how to work with Splunk in automated manner (see in appendix). But after their decision to stop their business in Russia last year, including customer support and selling software and services, it was just a matter of time for me to start working with other dashboarding tools.
For me, Grafana has become such a tool. In this post I want to describe the basic API operations with Grafana dashboards, which are necessary if you need to create and update dozens and hundreds of dashboards. Doing all this in the GUI will be painful. Grafana has a pretty logical and well-documented API. The only tricky moments I had were getting a list of all dashboard and editing an existing dashboard.
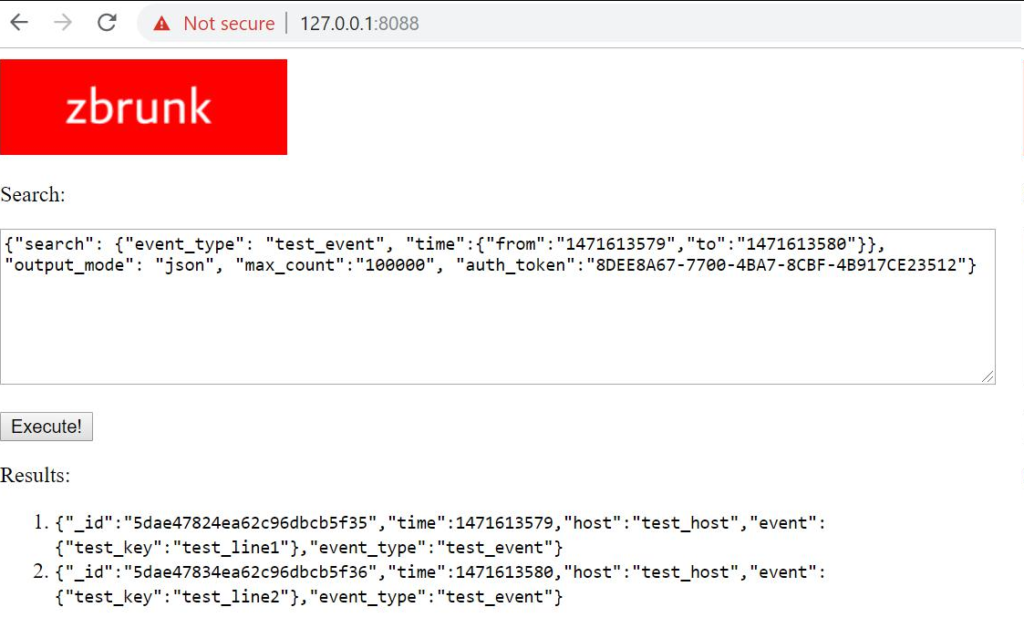
I also changed the priorities. Now I think it would be better not to integrate with Grafana, but to create own dashboards and GUI. And to begin with, I created a simple interface for Searching (and Deleting) events.
upd. 16.12.2019
A small update on Zbrunk. First of all, I created a new API call that returns a list of object types in the database and number of this types for a certain period of time. Without it, debugging was rather inconvenient.
I also added some examples of working with Zbrunk http API from python3. Rewriting them from pure curl was not so trivial. ? Flask is rather moody, so I had to abandon the idea of making requests exactly the same as in Splunk. ? But the differences are cosmetic. It is now assumed that events will be passed to collector in valid json (not as a file with json events separated by ‘\n’). I also send all params of requests as json, not data. But for the compatibility reasons previous curl examples will also work. ?
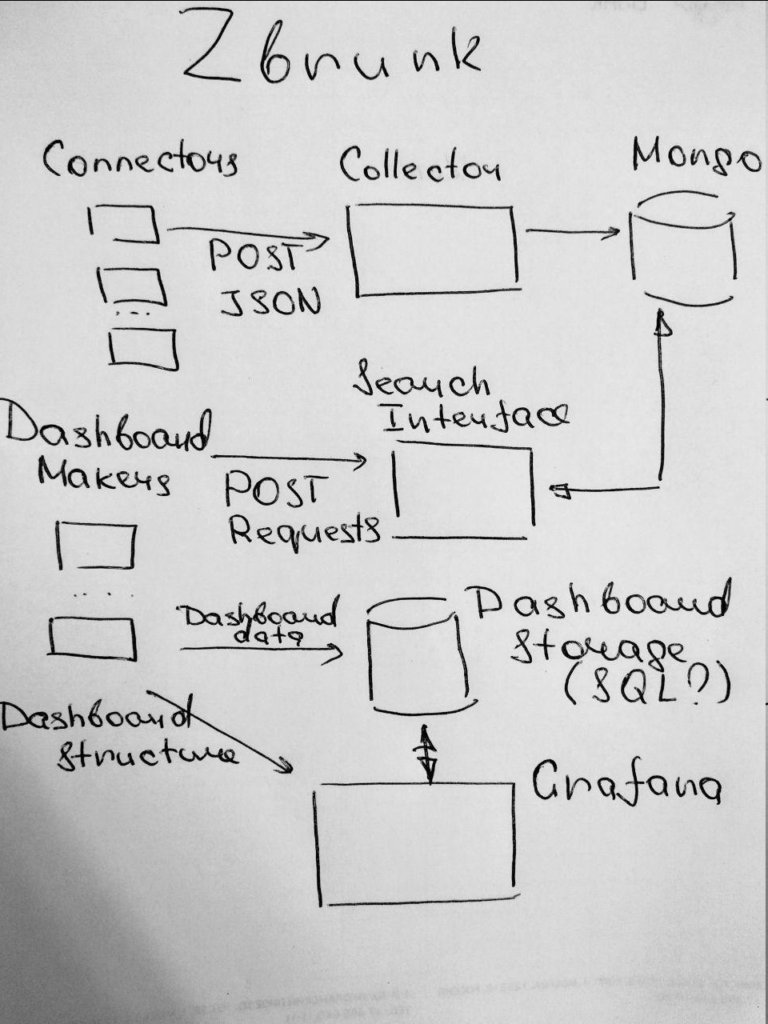
Zbrunk project (github) began almost like a joke. And in a way it is. ? In short, my friends and I decided to make an open-source (MIT license) tool, which will be a kind of alternative to Splunk for some specific tasks. So, it will be possible to:
Put structured JSON events in Zbrunk using http collector API
Get the events from Zbrunk using http search API
Make information panels based on these search requests and place them on dashboards
Why is it necessary? Well, I’ve worked a lot with Splunk in recent years. I like the main concepts, and I think working with the events is a very effective and natural way of processing and presenting data. But for my tasks (Asset Management, Compliance Management, Vulnerability Management) with several hundred megabytes of raw data per day to process and dashboards that need to be updated once or several times a day Splunk felt like an overkill. You really don’t need such performance for these tasks.
And, considering the price, it only makes sense if your organization already uses Splunk for other tasks. After Splunk decision to leave Russian market, this became even more obvious, so many people began to look for alternatives for possible and, as far as possible, painless migration.
We are realistic, the performance and search capabilities of Zbrunk will be MUCH worse. It’s impossible to make such universal and effective solution as a pet project without any resources. So, don’t expect something that will process terabytes of logs in near real time, the goal is completely different. But if you want same basic tool to make dashboards, it worth a try. ?
Now, after first weekend of coding and planning it’s possible to send events to Zbrunk just like you do it using the Splunk HTTP Event Collector and they appear in MongoDB:
Thus, it will be very easy to use your existing custom connectors if you already have some. The next step is to make basic http search API, prepare dashboard data using these search requests and somehow show these dashboards, for example, in Grafana. Stay tuned and welcome to participate. ?
This is my personal blog. The opinions expressed here are my own and not of my employer. All product names, logos, and brands are property of their respective owners. All company, product and service names used here for identification purposes only. Use of these names, logos, and brands does not imply endorsement. You can freely use materials of this site, but it would be nice if you place a link on https://avleonov.com and send message about it at me@avleonov.com or contact me any other way.