
VM Remediation using external task tracking systems. In previous post I have briefly reviewed built-in remediation capabilities of vulnerability management systems. Continuing the theme, today I want to share some basic concepts how vulnerability remediation can be managed using external task tracking systems (Jira, TFS, Testrack, etc).
Pros: it makes possible to implement any logic of remediation/patch management process.
Cons: you should make it by yourself; scripting skills and API knowledge required.
Tickets in buit-in remediation systems are usually assigned per host or per vulnerability. However, for large size networks making “one vulnerability on one host – one ticket” quickly become impractical. With universal task trackers we can do it in a different ways. I find it most convenient to make tickets on principle “one category of vulnerabilities, one ip range, one scanning iteration – one ticket”.
Category of vulnerabilities may depend on the vulnerability types, ways of remediation and criticality. For example, it can be a type of detection plugin “Windows security bulletins” or more complex “Windows security bulletins with high/critical vulnerabilities and available public exploits”).
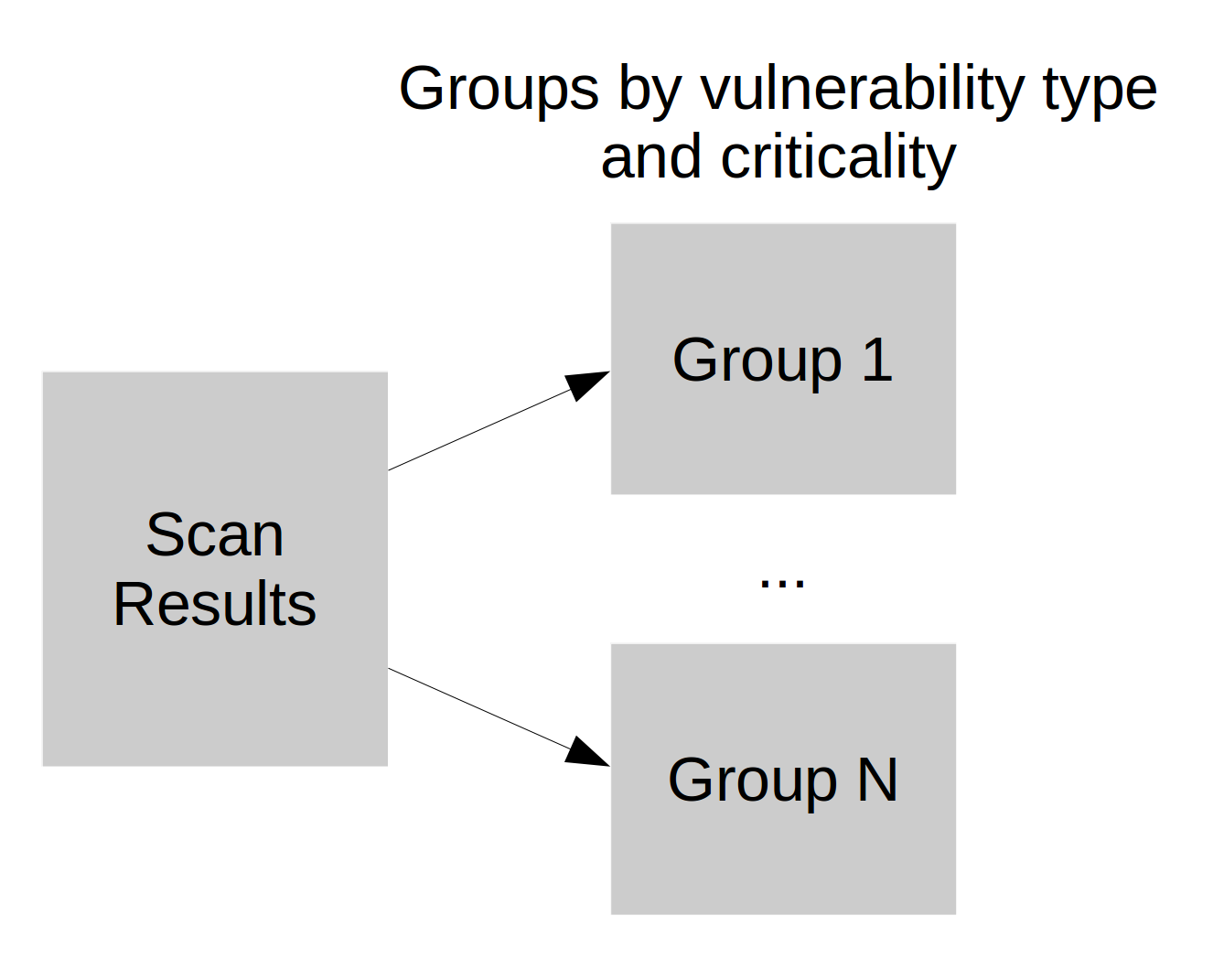
IP range depends on the particular group of administrators who will solve the issue. As a rule, it is not practical to make one large task for various administrators groups. This may lead to blurring of responsibility.
Iteration number depends on the scan frequency in organization: once a month, week, day, etc. For weekly scans you can use calendar week number.
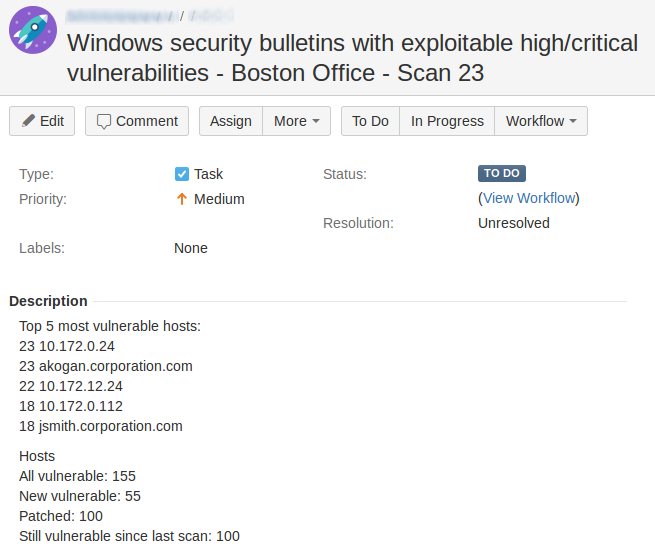
Thus, in ticket title will be something like “Windows security bulletins with exploitable high/critical vulnerabilities – Boston Office – Scan 23”. You can also assign a ticket identifier that uniquely characterizes the range, iteration and category of vulnerabilities.

In description of the ticket you can specify statistics for the vulnerable hosts:
- Top 5-10 most vulnerable hosts (“pay special attention to them”)
- The number of vulnerable hosts (“current situation”)
- The number of new vulnerable hosts emerged from the last scan (“patch it to close the ticket!”)
- The number of hosts that become safe since the last scan (“good job – patch management process is working”)
- The number of vulnerable hosts, that were vulnerable in the last scan and now remains vulnerable (“lack of patch management process”)
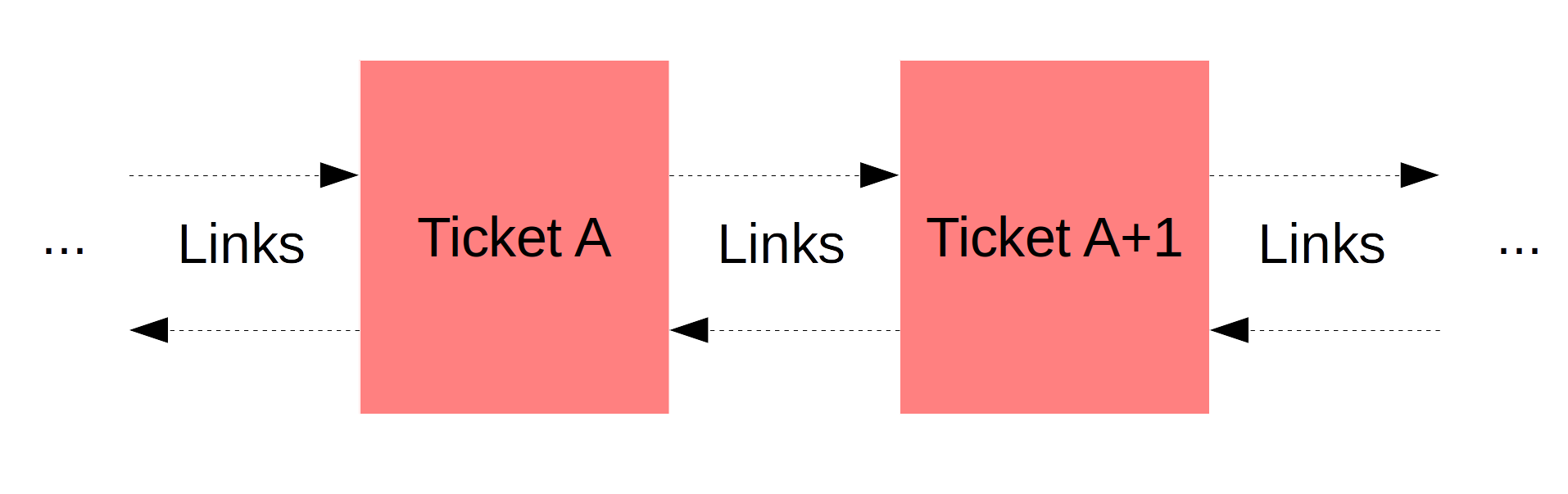
It is assumed that administrators will patch only new vulnerabilities within the ticket. Older vulnerabilities should be fixed in previous ticket, where they have been detected for the first time. It is may be convenient to add references to the previous and next scan tickets for easy navigation.
Complete lists of the hosts and vulnerabilities may be attached to the ticket. It is easy to produce such differential reports with scan results, collected, for example, using Nexpose API, presented in parsable form. For example, in csv containing the fields:
- ip-address
- hostname
- category of vulnerability
- vulnerabilit id (detection plugin id)
- vulnerability title
- vulnerability description

Hi! My name is Alexander and I am a Vulnerability Management specialist. You can read more about me here. Currently, the best way to follow me is my Telegram channel @avleonovcom. I update it more often than this site. If you haven’t used Telegram yet, give it a try. It’s great. You can discuss my posts or ask questions at @avleonovchat.
А всех русскоязычных я приглашаю в ещё один телеграмм канал @avleonovrus, первым делом теперь пишу туда.
Pingback: Retrieving scan results with Nessus API | Alexander V. Leonov
Pingback: Retrieving scan results through Nessus API | Alexander V. Leonov
Pingback: Nessus V2 xml report format | Alexander V. Leonov
Pingback: F-Secure Radar Ticketing | Alexander V. Leonov
Pingback: ZeroNights16: Enterprise Vulnerability Management | Alexander V. Leonov
Pingback: Automated task processing with JIRA API | Alexander V. Leonov
Pingback: Rapid7 Nexpose in 2017 | Alexander V. Leonov