
New Year holidays in Russia lasts 10 days this year! Isn’t it an excellent opportunity to start a new project? So, I decided to make my own active network vulnerability scanner – Vulchain.
Why? Well, first of all, it’s fun. You can make the architecture from scratch, see the difficulties invisible from the user side and try something new in software development as well.
Basic principles of the project. This is not a dogma, but rather a general direction.
- Data layers. I would like to have this independent sets of data:
- Raw data collections
- Software versions detected from the raw data
- Vulnerabilities detected from the software versions
- Exploitability assessment data for the detected vulnerabilities
- Modularity. Most of functionality will be performed by the independent modules which read some data from one data level, and create some data on other data level.
- Transparency. Data is stored constantly on the all levels. You can easily figure out how the data was processed, track the errors and modify modules.
- Neutrality. All modules are independent and easily replaceable. For example:
- You can use Nmap or other port scanner to detect services. You can refuse active scanning completely and collect data from local agents or from your cmdb.
- You can use the Vulners Burp API and Linux Audit API to detect software vulnerabilities, use can use some other service or you can write your local detection scripts using NVD or Vulners Collections (see also “Vulnerability Assessment without Vulnerability Scanner“).
- Rationality. If it is possible to use some security utility, service or product, we will integrate with them, rather than writing our own analogue. We spend resources only on what will give us the maximum profit at a minimum of costs. 😉
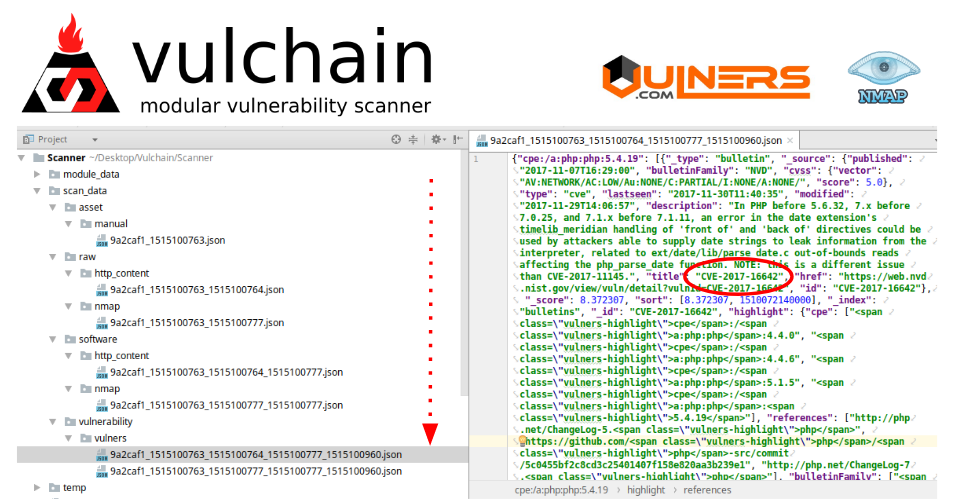
And as you can see at Pycharm screenshot above, POC is already working. Data is now stored in JSON because it’s easier to debug. It will be probably stored in some nosql database later.
- I create Assets with IP, hostname and description.
- http_content and nmap modules collect the raw data for the assets.
- Individual modules extract information about software / services from these raw data and save it unified format.
- And finally, there is a module, in this case vulners, which takes information about software / services and creates json files with detected vulnerabilities.
Pros:
- It is much easier to debug code and add new modules.
- The loss of data is minimal, it is clear how all of the detections were made.
- You can perform “scan without scanning”. On service data updates (rules for software and vulnerability detection), you can reprocess only certain data levels. There is no need to actively manipulate with the host each time.
Cons:
- Some redundancy in the code and stored data.
In short, the process has begun. :-). I will be happy to answer your comments and questions. Next I am going to make first sketches of API and GUI and add modules for authenticated scanning.

Hi! My name is Alexander and I am a Vulnerability Management specialist. You can read more about me here. Currently, the best way to follow me is my Telegram channel @avleonovcom. I update it more often than this site. If you haven’t used Telegram yet, give it a try. It’s great. You can discuss my posts or ask questions at @avleonovchat.
А всех русскоязычных я приглашаю в ещё один телеграмм канал @avleonovrus, первым делом теперь пишу туда.
Pingback: New Nessus 7 Professional and the end of cost-effective Vulnerability Management (as we knew it) | Alexander V. Leonov
Pingback: Vulchain scan workflow and search queries | Alexander V. Leonov