My last post about Guinea Pigs and Vulnerability Management products may seem unconvincing without some examples. So, let’s review one. It’s a common problem that exists among nearly all VM vendors, I will demonstrate it on Tenable Nessus.
If you perform vulnerability scans, you most likely seen these pretty huge checks in your scan results like “KB4462917: Winsdows 10 Version 1607 and Windows Server 2016 October 2018 Security Update“. This particular Nessus plugin detects 23 CVEs at once.
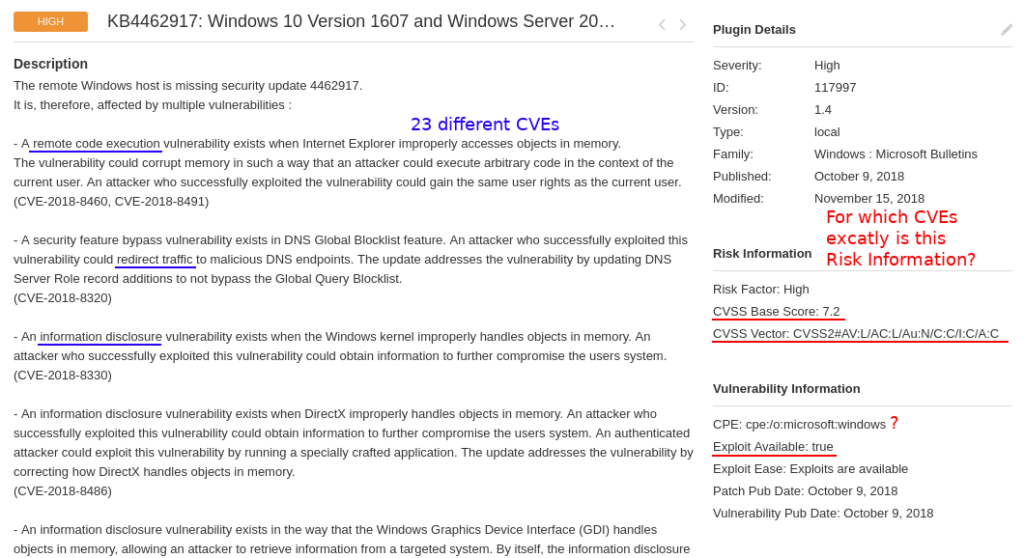
And, as you can see, it has formalized “Risk Information” data in the right column. There is only one CVSS score and vector, one CPE, one exploitability flag, one criticality level. Probably because of architectural limitations of the scanner. So, two very simple questions:
- for which CVE (of these 23) is this formalized Risk Information block?
- for which CVE (of these 23) exploit is available?
Ok, maybe they show CVSS for the most critical (by their logic) CVE. Maybe they somehow combine this parameter from data for different CVEs. But in most cases this will be inaccurate. Risk information data for every of these 23 vulnerabilities should be presented independently.
As you can see on the screenshot, one of these vulnerabilities is RCE the other is Information Disclosure. Vulnerability Management solution tells us that there is an exploit. Is this exploit for RCE or DoS? You should agree, that it can be crucial for vulnerability prioritization. And more than this, in the example there are 7 different RCEs in Internet Explorer, MSXML parser, Windows Hyper-V, etc. All this mean different attack scenarios. How is it possible to show it Vulnerability Scanner like one entity with one CVSS and exploitability flag? What can the user get from this? How to search in all this?
Continue reading