
My last post about Guinea Pigs and Vulnerability Management products may seem unconvincing without some examples. So, let’s review one. It’s a common problem that exists among nearly all VM vendors, I will demonstrate it on Tenable Nessus.
If you perform vulnerability scans, you most likely seen these pretty huge checks in your scan results like “KB4462917: Winsdows 10 Version 1607 and Windows Server 2016 October 2018 Security Update“. This particular Nessus plugin detects 23 CVEs at once.
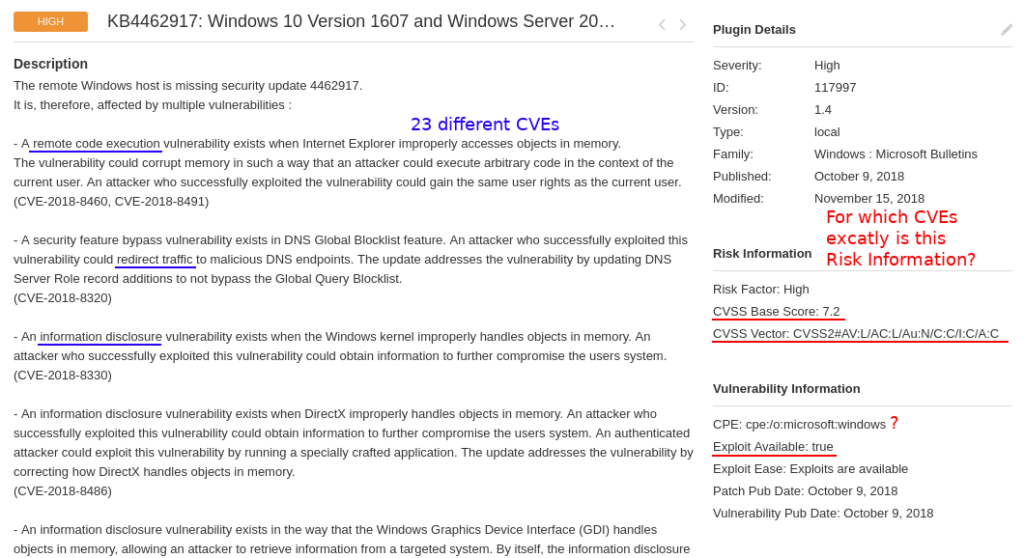
And, as you can see, it has formalized “Risk Information” data in the right column. There is only one CVSS score and vector, one CPE, one exploitability flag, one criticality level. Probably because of architectural limitations of the scanner. So, two very simple questions:
- for which CVE (of these 23) is this formalized Risk Information block?
- for which CVE (of these 23) exploit is available?
Ok, maybe they show CVSS for the most critical (by their logic) CVE. Maybe they somehow combine this parameter from data for different CVEs. But in most cases this will be inaccurate. Risk information data for every of these 23 vulnerabilities should be presented independently.
As you can see on the screenshot, one of these vulnerabilities is RCE the other is Information Disclosure. Vulnerability Management solution tells us that there is an exploit. Is this exploit for RCE or DoS? You should agree, that it can be crucial for vulnerability prioritization. And more than this, in the example there are 7 different RCEs in Internet Explorer, MSXML parser, Windows Hyper-V, etc. All this mean different attack scenarios. How is it possible to show it Vulnerability Scanner like one entity with one CVSS and exploitability flag? What can the user get from this? How to search in all this?
It’s not an idle question, because Vulnerability Management vendors use this formalized data as a base for further analysis. So, when I see that some traditional VM vendor presents yet another SEIM-like functionality with searches, prioritization and dashboards, it doesn’t really impress me, because I know that the underlying data might be too trashy for actual decision making.
How does such plugins appear in VM vendor’s Knowledge Bases?
It’s not a secret that the most of vulnerabilities (I think it’s fair to say that more than 80%) described in the VM vendor’s Knowledge Base come directly from the software vendors. In most cases in somehow automated manner.
It looks like this:
- Some Software Vendor publishes a patch description, usually called “security bulletin”, describing the vulnerabilities found in the software: what are they about and how they can be fixed. The examples of such bulletins for different vendors: Microsoft MS and KB, RedHat RHSA and CESA, Ubuntu USN, Cisco SA, etc. Tones of them. Read more in “Vulnerability Databases: Classification and Registry“.
- The VM vendor figures out how to check that vulnerabilities described in the bulletin are fixed on a host. In most cases it means to check that some software version or/and patch(es) were installed during some authenticated scan. For some systems it’s relatively easy, you even can easily do it by yourself, see”Vulnerability Assessment without Vulnerability Scanner“. For others, it may be tricky because of cumulative patches and weird secretive policies of software vendors. But anyway, if the vulnerabilities are NOT fixed on a host it shows vulnerability description the security bulletin as is.
This scheme is convenient for Software Vendors, because they think in the terms of bugs and patches. It convenient for VM vendors as well, because they use data as is, and, technically, they do everything right. You don’t have a patch? This means that you have vulnerabilities. Here is a list. Patch it.
It’s only inconvenient for the end-user, because the data he gets is not actionable. He will need to spend his time on figuring what actual vulnerabilities are there, think about attack vectors and real exploitability. And they should use these barely useful reports to convince IT to make patching.
How to make it better?
It’s necessary to go much deeper in analyzing vulnerability descriptions, address each Vulnerability independently and how they can be combined by an attacker. For VM vendors this means that they should start to process descriptive data and store it differently. For example, in case of Nessus it might be helpful to add more tags to NASL and describe vulnerability as a complex structure. This certainly will require changes in all enterprise-level products as well, as Security Center or Tenable.io.
I write all this not to criticize any vendor, especially not to criticize Tenable. BTW, Tenable became the best Vulnerability Management vendor of 2018 according to the poll in my Telegram Channel. And it seems quite fair to me. But there is a status quo: every major VM vendor on the market work with vulnerability data like this. And they won’t make massive changes until the customers signal that this is important.
What can we do right now?
Until then it’s possible to do this additional processing with your own scripts by analyzing the plugin descriptions from Nessus2 reports, and bringing additional data from NVD and Vulners.
Or you can buy a separate a solution for this, like Kenna, which has it’s own issues, but way better than nothing. But for me the situation seem weird a bit, when you have to
- buy a vulnerability management solution to detect the issue
- buy another vulnerability management solution to make the output from the first one actionable
Maybe it’s good for the seller, but definitely not good for the customer. 🙂 And it basically means that the first VM solution could do it’s job much better.

Hi! My name is Alexander and I am a Vulnerability Management specialist. You can read more about me here. Currently, the best way to follow me is my Telegram channel @avleonovcom. I update it more often than this site. If you haven’t used Telegram yet, give it a try. It’s great. You can discuss my posts or ask questions at @avleonovchat.
А всех русскоязычных я приглашаю в ещё один телеграмм канал @avleonovrus, первым делом теперь пишу туда.
Pingback: No left boundary for Vulnerability Detection | Alexander V. Leonov
Hi Alexander,
Nice post! I largely agree with what you’ve written here. But (full disclosure: I’m a Product Manager at Rapid7), I’d be remiss not to point out that over the last several years, InsightVM and Nexpose have been moving away from the patch-centric approach you described.
Even though assessment of vulnerabilities may be based on whether a patch is present, each vulnerability a patch is meant to remediate gets independently broken out in order to more accurately model risk. We wrote a blog post about this back in 2015: https://blog.rapid7.com/2015/10/29/increasing-risk-visibility/ — and we’ve since made similar changes for all of our Linux coverage as well as for Microsoft (see this post: https://blog.rapid7.com/2017/02/06/a-reminder-about-upcoming-microsoft-vulnerability-content-changes/).
Hi Greg! Thanks for a great comment! This approach of Nexpose is much better, indeed. 😉
Pingback: Vulnerability Management at Tinkoff Fintech School | Alexander V. Leonov
Pingback: Code IB 2019: Vulnerability Management Masterclass | Alexander V. Leonov
Pingback: PHDays9: new methods of Vulnerability Prioritization in Vulnerability Management products | Alexander V. Leonov