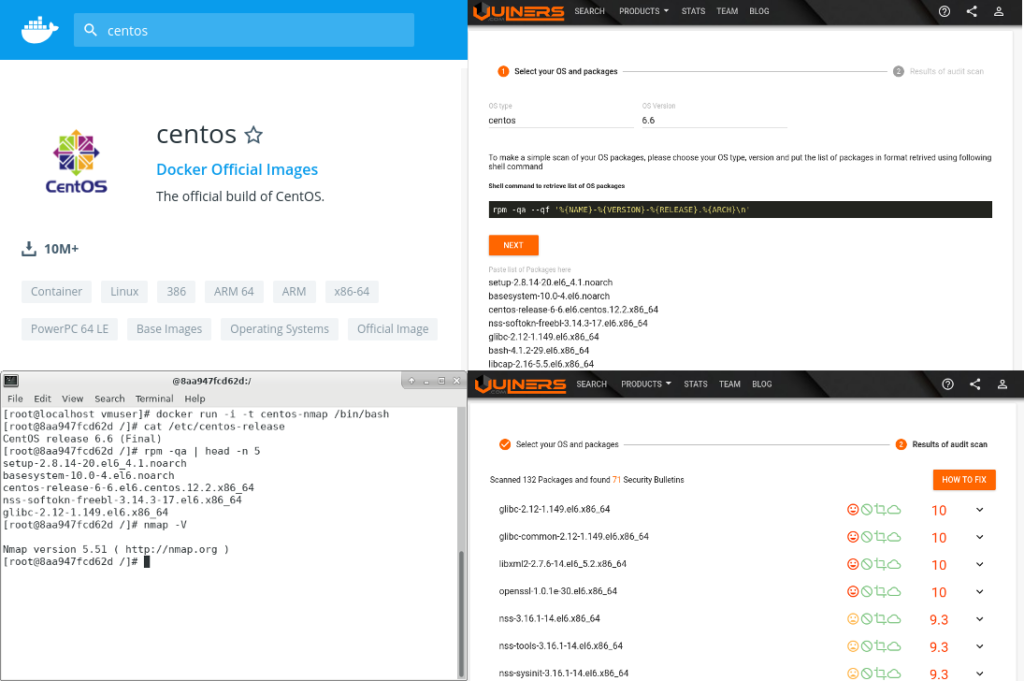
Docker and containerization are literally everywhere. IMHO, this changes the IT landscape much more than virtualization and clouds. Let’s say you have a host, you checked it and find out that there are no vulnerable packages. But what’s the point if this host runs Docker containers with their own packages that may be vulnerable? Add to this the issues with complex orchestration systems, such as Kubernetes, completely different DevOps subculture with their own terms, slang, beliefs, priorities, and the situation begins to look like complete IT Hell. 🙂
But it seems that Docker will be here for a long time, so we will have to live with it. 😉 Here I will not write what Docker is and how it works. There are many publications about this. I personally interested in what actually we can do with these weird “virtual machines”, how can we run and assess them.
The world is becoming increasingly dependent on information technologies.
Government. More and more states provide digital services for their citizens and rely complex information systems.
Business. There are no more companies that do not have IT infrastructure (on-premises or cloud). IT processes become the most valuable competitive advantages of the companies.
People. The number of active Internet users is steadily growing. People own a large number of connected devices: from desktops and smartphones to smart homes and cars. Electronic payments (bank cards, Apple pay, PayPal, etc.) replace cash and traditional banking tools.
All these information systems make our life easier and more efficient. They also create the need for a huge amount of various software. This software is developed by people. And people tend to make mistakes. Especially when security is not their priority (when speed is a priority, for example). These errors cause large number of vulnerabilities exploited by attackers.
Regularly, we can hear about exploitation cases that often lead to significant damage. Who should protect us from cyber threats and cybercrime?
It’s another common problem in nearly all Vulnerability Management products. In the post “What’s wrong with patch-based Vulnerability Management checks?” I wrote about the issues in plugin descriptions, now let’s see what can go wrong with the detection logic.
The problem is that Vulnerability Management vendors, in many cases, have no idea which versions of the Software were actually vulnerable.
OMG?! How this can be true? 🙂 Let’s take an example.
Each vulnerability at some points in time:
was implemented in the program code as a result of some mistake (intentional or not)
Let’s suppose that we have some Software A with released versions 1, 2 … 20.
Just before the release of version 10, some programmer made a mistake (bug) in the code and since the version 10 Software A has become critically vulnerable. Before the release of version 20, Software Vendor was informed about this vulnerability and some programmer fixed it in version 20. Then Software Vendor released a security bulletin: “Critical vulnerabilities in the Software A. You are not vulnerable if you have installed the latest version 20.”
And what does Vulnerability Management vendor? This vendor only sees this security bulletin. It is logical for him to decide that all versions of Software A starting from 1 are vulnerable. So, it will mark installed versions 1 … 9 of the Software A as vulnerable, even so actually they are NOT.
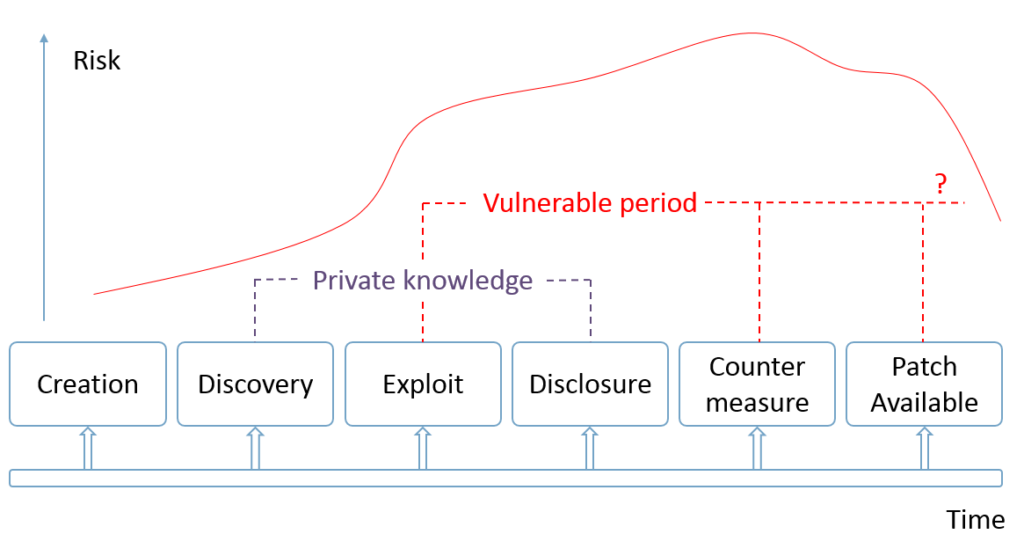
Vulnerability Life Cycle diagram shows possible states of the vulnerability. In a previous post I suggested to treat vulnerabilities as bugs. Every known vulnerability, as same as every bug, was implemented by some software developer at some moment of time and was fixed at some moment of time later. What happens between this two events?
Right after the vulnerability was implemented in the code by some developer (creation) nobody knows about it. Well, of course, if it was done unintentionally. By the way, making backdoors look like an ordinary vulnerabilities it’s a smart way to do such things. 😉 But let’s say it WAS done unintentionally.
Time passed and some researcher found (discovery) this vulnerability and described it somehow. What’s next? It depends on who was that researcher.
It looks like a pretty simple question. I used it to started my MIPT lecture. But actually the answer is not so obvious. There are lots of formal definitions of a vulnerability. For example in NIST Glossary there are 17 different definitions. The most popular one (used in 13 documents) is:
Vulnerability is a weakness in an information system, system security procedures, internal controls, or implementation that could be exploited or triggered by a threat source NISTIR 7435 The Common Vulnerability Scoring System (CVSS) and Its Applicability to Federal Agency Systems
But I prefer this one, it’s from the glossary as well:
Vulnerability is a bug, flaw, weakness, or exposure of an application, system, device, or service that could lead to a failure of confidentiality, integrity, or availability.
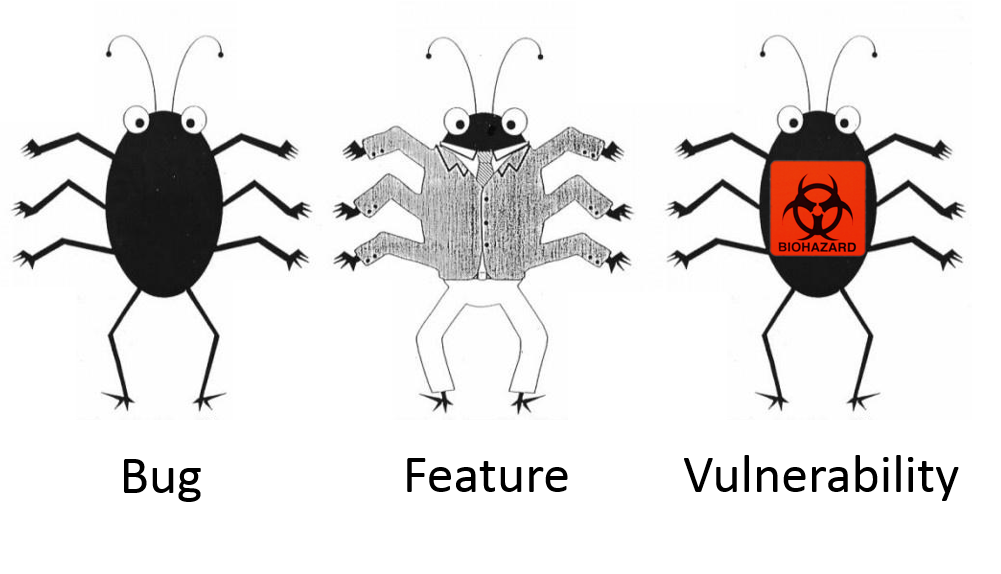
I think the best way to talk about vulnerabilities is to treat them as bugs and errors. Because people deal with such entities more often in a form of software freezes and BSODs. 😉
You probably heard a joke, that a bug can be presented as a feature if it is well-documented and the software developers don’t want to fix it.
Vulnerability is also a specific bug that can lead to some security issues. Or at least it is declared.
My last post about Guinea Pigs and Vulnerability Management products may seem unconvincing without some examples. So, let’s review one. It’s a common problem that exists among nearly all VM vendors, I will demonstrate it on Tenable Nessus.
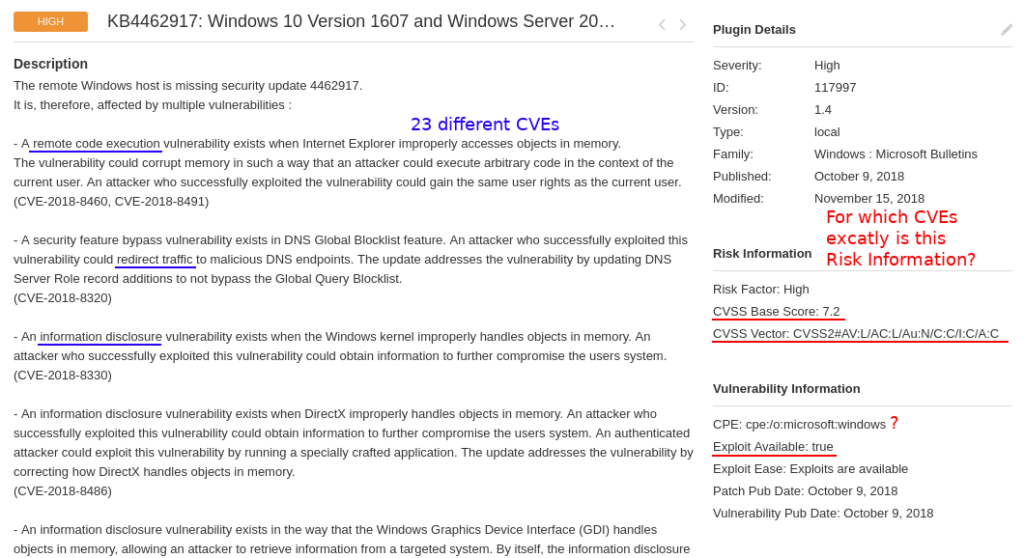
And, as you can see, it has formalized “Risk Information” data in the right column. There is only one CVSS score and vector, one CPE, one exploitability flag, one criticality level. Probably because of architectural limitations of the scanner. So, two very simple questions:
for which CVE (of these 23) is this formalized Risk Information block?
for which CVE (of these 23) exploit is available?
Ok, maybe they show CVSS for the most critical (by their logic) CVE. Maybe they somehow combine this parameter from data for different CVEs. But in most cases this will be inaccurate. Risk information data for every of these 23 vulnerabilities should be presented independently.
As you can see on the screenshot, one of these vulnerabilities is RCE the other is Information Disclosure. Vulnerability Management solution tells us that there is an exploit. Is this exploit for RCE or DoS? You should agree, that it can be crucial for vulnerability prioritization. And more than this, in the example there are 7 different RCEs in Internet Explorer, MSXML parser, Windows Hyper-V, etc. All this mean different attack scenarios. How is it possible to show it Vulnerability Scanner like one entity with one CVSS and exploitability flag? What can the user get from this? How to search in all this?
Atlassian Jira is a great tool for organizing Agile processes, especially Scrum. But managing Scrum Sprints manually using Jira web GUI maybe time consuming and annoying. So, I decided to automate some routine operations using JIRA API and Python.
I will use my domain account for authentication. First of all let’s see how to get Jira Scrum Board ID by it’s name and get all the Sprints related to the Board.
This is my personal blog. The opinions expressed here are my own and not of my employer. All product names, logos, and brands are property of their respective owners. All company, product and service names used here for identification purposes only. Use of these names, logos, and brands does not imply endorsement. You can freely use materials of this site, but it would be nice if you place a link on https://avleonov.com and send message about it at me@avleonov.com or contact me any other way.