
November 2023 – January 2024: New Vulristics Features, 3 Months of Microsoft Patch Tuesdays and Linux Patch Wednesdays, Year 2023 in Review. Hello everyone! It has been 3 months since the last episode. I spent most of this time improving my Vulristics project. So in this episode, let’s take a look at what’s been done.
Alternative video link (for Russia): https://vk.com/video-149273431_456239139
Also, let’s take a look at the Microsoft Patch Tuesdays vulnerabilities, Linux Patch Wednesdays vulnerabilities and some other interesting vulnerabilities that have been released or updated in the last 3 months. Finally, I’d like to end this episode with a reflection on how my 2023 went and what I’d like to do in 2024.
New Vulristics Features
Vulristics JSON input and output
In Vulristics you can now provide input data in JSON format and receive output in JSON format. Which opens up new opportunities for automation.
Simply provide a list of CVEs and comments for them (if you have them) as input, and the output will be rated CVEs (with vulnerability type, product, exploitation in the wild, public exploits, etc.).
You can create reports in both JSON and HTML format at the same time:
python3 vulristics.py --report-type "custom_profile" --profile-json-path "profile.json" --cve-data-sources "ms,nvd,epss,attackerkb,vulners,custom" --result-formats "json,html" --result-json-path "results.json" --result-html-path "results.html" --rewrite-flag "True"As an example, I uploaded a JSON file with a task for Vulristics (January Linux Patch Wednesday). In the JSON task file, you can specify the name of the report, a list of CVE identifiers and comments for them.
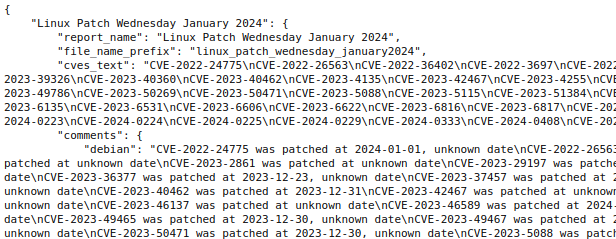
I’ve also uploaded a sample JSON results file. This file contains the same information as a regular HTML report. You can see there information on products and vulnerabilities related to them.
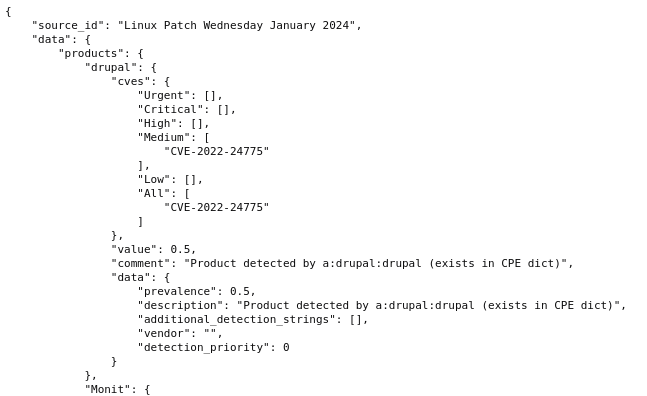
There is also a block with vulnerabilities, which contains information about each analyzed vulnerability: their overall criticality (vvs) and the described components that affected it.

JSON input and output combined with other Vulristics features make it a very flexible tool:
🔹A Custom Data Source allows you to use any vulnerability data you know about in Vulristics. Including the existence of an exploit and signs of exploitation in the wild. Thus, even non-public data can be used when prioritizing vulnerabilities.
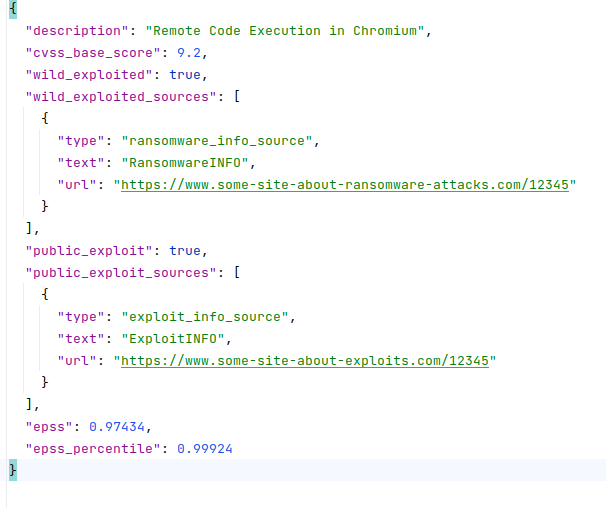
🔹 You can control the detection of a vulnerable product and set the prevalence of that product (which affects the final vulnerability score) by editing the products.json file. You can set keywords for detection there and increase or decrease the detection priority.
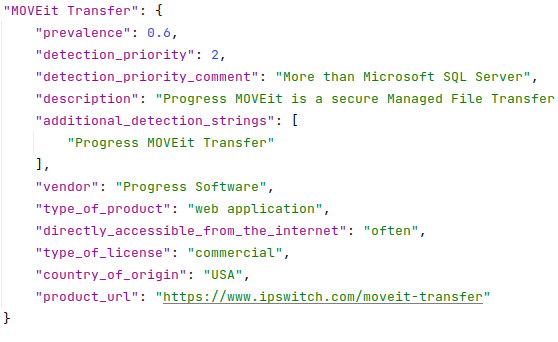
🔹 In a similar way, you can control the detection of vulnerability types and their criticality in the data_classification_vulnerability_types.py file.

CPE-based vulnerable product names detection
Let’s now talk in more detail about detecting a vulnerable product for a specific CVE. Vulristics had problems with these. Especially when I used it to analyze Linux Patch Wednesdays. For more than half of the vulnerabilities, Vulristics could not detect the related vulnerable products. 🤷♂️ Types of vulnerabilities too. But there were most problems with the products. Of course, it would be possible to manually add detection rules for them, but this would require too much time and effort.
So instead, I decided to take the time to implement detection based on short CPE IDs (type:vendor:product).
I take these IDs from NVD Data Source.
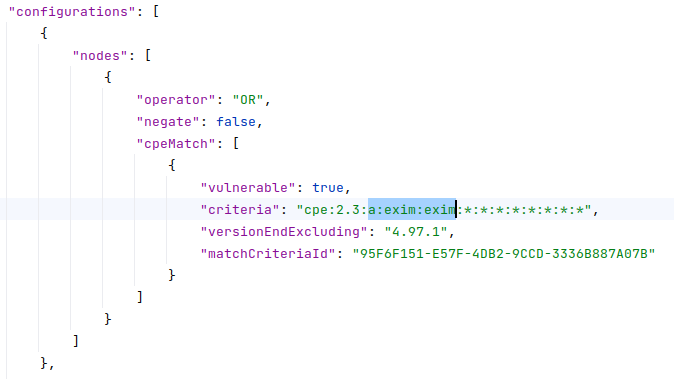
I add the same identifiers to the product descriptions in products.json.
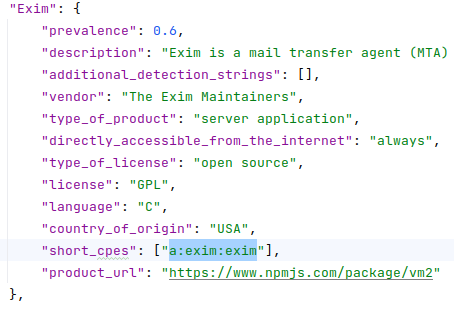
The work is in progress, but the reports are already much more informative even if the affected product is not described in products.json. 🙂

Vulristics now uses a combined method to detect vulnerable product names based on CPE IDs and keywords.
- The highest priority is given to the product name directly specified in the data source.
- Then the product name detected heuristically based on a description with a strict structure (for now only for Microsoft vulnerabilities).
- Then the product name detected by keywords (expressions).
- Then the product name detected by CPE identifiers.
In CPE detections, I give the highest priority to the first identifier of type a (application), if it is not there, then h (hardware), if it is not there, then o (operating system).
CWE-based vulnerability type detection
I solved the problem with detecting types of vulnerabilities in a similar way. Now Vulristics can detect vulnerability types not only by keywords (expressions), but also by CWE identifiers from NVD Data source.

For each vulnerability type in Vulristics, you can specify a set of corresponding CWE IDs in data_classification_vulnerability_types.py file. I’ve already mapped some CWE IDs to Vulristics vulnerability types. But, of course, not all of them. There are over 600 CWE IDs! I will add them as needed.
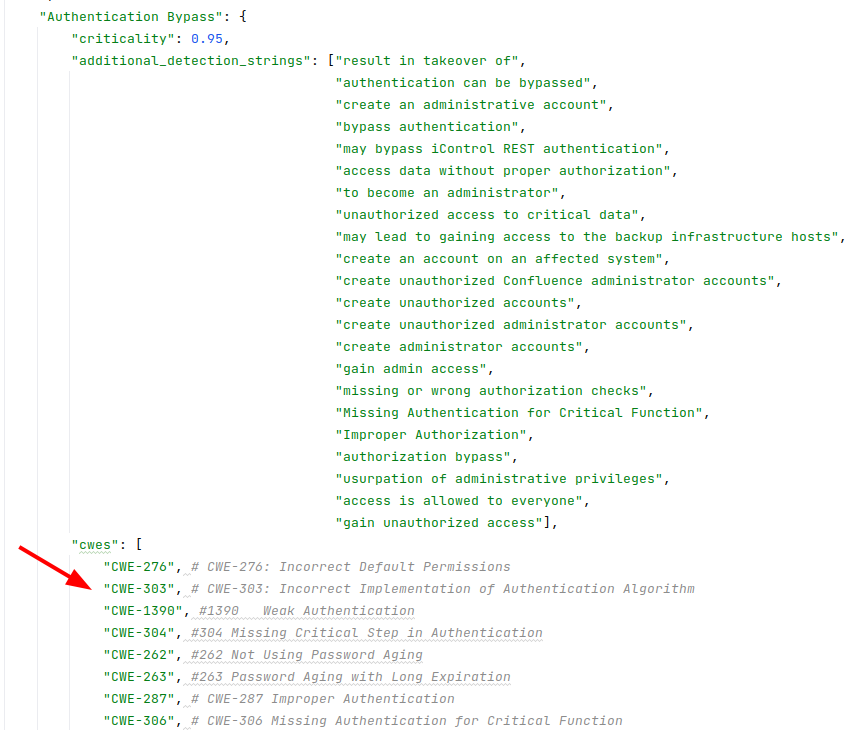
Additionally, I made the following changes to Vulristics vulnerability type detection:
🔹 I have added a new Incorrect Calculation vulnerability type for massive non-critical vulnerabilities that are not memory related (and therefore can’t be classified as Memory Corruption). For example, “Divide By Zero” or “Integer Overflow”. In fact, such vulnerabilities are simply bugs, because it is not clear from the description how an attacker can exploit them. If they lead to an application crash or RCE, then why not write about this directly? And if they don’t, then why bother? In my opinion, it would be better not to create CVE identifiers for such problems at all. But in fact, there are such CVE identifiers (especially often for Linux). Therefore, it is necessary to detect the type for such “vulnerabilities”. Now they will be classified as Incorrect Calculation with a relatively low criticality (same as Memory Corruption).

🔹 I started to get annoyed by Path Traversal vulnerabilities, which in fact give an attacker the ability to read and write arbitrary files. 🤷♂️ Therefore, for such vulnerabilities I will use the types Arbitrary File Reading (already existed) and Arbitrary File Writing (a new one).
🔹 I adjusted the weights for the types of vulnerabilities. The logic is this: the more specific the type and the more clear how this type of vulnerability can be used by an attacker, the greater the weight. But this thing, of course, is extremely subjective and I will most likely tweak it many more times. In the moment it looks like this:
Remote Code Execution 1.0
Code Injection 0.97
XXE Injection 0.97
Command Injection 0.97
Authentication Bypass 0.95
Arbitrary File Writing 0.95
Security Feature Bypass 0.90
Elevation of Privilege 0.85
Information Disclosure 0.83
Arbitrary File Reading 0.83
Cross Site Scripting 0.8
Open Redirect 0.75
Path Traversal 0.7
Denial of Service 0.7
Memory Corruption 0.5
Incorrect Calculation 0.5
Spoofing 0.4
Tampering 0.3
Unknown Vulnerability Type 0Right now it seems like XSS and Open Redirect are a little underrated. But on the other hand, they require more human interaction, so maybe that’s okay. 🤔 In any case, although the type of vulnerability affects the final criticality quite strongly, it does not affect as much as the presence of an exploit and signs of exploitation in the wild.
Linux Patch Wednesday
As part of this project, I am analyzing Linux vulnerabilities that have been patched in the last month. The main difficulty in distributing CVEs by month is to determine the date when the CVE was patched for the first time. Usually the Debian team is the fastest to patch vulnerabilities. But the problem is that some Debian OVAL definitions do not have a publication date. 😑
I’ll demonstrate this with an example. When I generated the Linux Patch Wednesday report for January, I saw in the report UnRAR Arbitrary File Overwrite (CVE-2022-30333). Why did the 2022 vulnerability appeared at the beginning of 2024? Because it was patched in Ubuntu recently, on January 8th. In this case, it was not the UnRAR utility that was fixed, but the third-party ClamAV library for anti-virus scanning of archives. Does this mean that Linux vendors did not patch this CVE vulnerability until 2024? Well, some Linux vendors did. There is a message on the Debian mailing list dated August 17, 2023. It’s also late, not 2022 (as it should be), but still a little earlier. But the problem is that this date, August 17, 2023, was not in the Debian OVAL content. And that’s why the CVE got from 2022 to 2024. Simply because the earliest (and only) date that was in the Linux vendors’ OVAL content for this vulnerability was the date of the belated fix in Ubuntu Linux. 🤷♂️
So, OVAL is good and universal, but, unfortunately, not a panacea. Surprisingly, there is also a mess there, which no one cares about. 😏
That’s why I had to learn how to parse archives of the Debian Security Bulletin mailing list. As a result, the list of vulnerabilities in LPW has become more adequate. In particular, CVE-2022-30333 went to the LPW for September 2023. And it is also possible to work with other mailing lists, for example with Suse, in the same manner.
From November to January there were between 81 and 192 CVEs in Linux Patch Wednesdays. Among them were vulnerabilities with public exploits and signs of active exploitation in the wild:
- Security Feature Bypass / RCE – ActiveMQ (CVE-2023-46604)
- Cross Site Scripting – Roundcube (CVE-2023-5631)
- Information Disclosure – WordPress (CVE-2023-39999)
There were also vulnerabilities with the signs of active exploitation in the wild, but without public exploits:
- Remote Code Execution – Safari (CVE-2023-42917)
- Information Disclosure – Safari (CVE-2023-42916)
- Incorrect Calculation – Chromium (CVE-2023-6345) Integer overflow in Skia
- Remote Code Execution – spreadsheet::parseexcel Perl module (CVE-2023-7101)
It makes no sense to list all the vulnerabilities for which there is a PoC or an exploit, but there are no signs of exploitation in the wild. Simply because there are a lot of them, about 90. You can look at them yourself in the Vulristics reports. I’ve updated the Vulristics reports for these Linux Patch Wednesdays on January 30th:
🗒 November Linux Patch Wednesday
🗒 December Linux Patch Wednesday
🗒 January Linux Patch Wednesday
Thanks to the latest improvements to Vulristics, I processed them to almost perfect condition. The product name and type of vulnerability were NOT detected only for “This candidate has been reserved…” stubs and for vulnerabilities with such a strange description that even manual processing is difficult.
Microsoft Patch Tuesdays
Over the past 3 months, Microsoft has been releasing Patch Tuesdays with relatively few CVEs. From 53 to 98, including vulnerabilities that were released between Patch Tuesdays.
At the moment, there is only one vulnerability with a public exploit and signs of exploitation in the wild:
Security Feature Bypass – Windows SmartScreen (CVE-2023-36025). To exploit the vulnerability, an attacker must convince a user to click on a specially crafted Internet Shortcut (.URL) or a hyperlink pointing to an Internet Shortcut file to be compromised by them.
Signs of exploitation in the wild have been noted for these vulnerabilities:
- Elevation of Privilege – Windows Cloud Files Mini Filter Driver (CVE-2023-36036)
- Elevation of Privilege – Windows DWM Core Library (CVE-2023-36033)
- Incorrect Calculation – Chromium (CVE-2023-6345). Integer overflow in Skia
- Memory Corruption – Chromium (CVE-2023-7024). Heap buffer overflow in WebRTC
PoCs have also appeared for these vulnerabilities. Most of them are EoPs. And VM vendors ignored most of these vulnerabilities in their Microsoft Patch Tuesday reviews.
- Remote Code Execution – Microsoft Excel (CVE-2023-36041)
- Elevation of Privilege – Windows Hyper-V (CVE-2023-36427)
- Elevation of Privilege – XAML Diagnostics (CVE-2023-36003)
- Elevation of Privilege – Windows Kernel (CVE-2024-20698)
- Elevation of Privilege – Visual Studio (CVE-2024-20656)
- Security Feature Bypass – Hypervisor-Protected Code Integrity (HVCI) (CVE-2024-21305)
- Memory Corruption – SQLite (CVE-2022-35737)
I’ve updated the Vulristics reports for these Microsoft Patch Tuesdays on January 29th:
🗒 November Microsoft Patch Tuesday
🗒 December Microsoft Patch Tuesday
🗒 January Microsoft Patch Tuesday
Other Vulnerabilities
Among the many other critical vulnerabilities that have appeared or been updated over the past 3 months, I would like to highlight the following:
- Sharepoint Authentication Bypass vulnerability (CVE-2023-29357) from June Patch Tuesday is in active exploitation. It was added to CISA KEV. Microsoft classifies this vulnerability as EoP, but the description is similar to AuthBypass. A remote, unauthenticated attacker can exploit the vulnerability by sending a spoofed JWT authentication token to a vulnerable server giving them the privileges of an authenticated user on the target. According to the advisory, no user interaction is required in order for an attacker to exploit this flaw. The vulnerability was demonstrated at Pwn2Own Vancouver in March 2023. And then, about six months after the patch was released, real attacks began. If you have a Sharepoint server in your infrastructure that has not been updated for more than six months, pay attention.
- Yet Another Apache Struts 2 RCE (CVE-2023-50164). Shadowserver also writes that there have been attempts to exploit it in the wild. Don’t delay patching.
- Ridiculous critical vulnerability in GitLab – Account Takeover via password reset without user interactions (CVE-2023-7028). 🤦♂️🙂 GitLab CE/EE versions from 16.1.0 are vulnerable. CVSS 10. Exploitation is trivial. Patches are available.
- Critical RCE in Atlassian Confluence (CVE-2023-22527). PT SWARM (Positive Technologies Offensive Team) successfully reproduced this vulnerability. AttackerKB, with reference to TheDFIRReport, states that active exploitation of this vulnerability has already begun
About the results of 2023
It was a great year for me, it’s hard to complain. 😇 I’m alive and feel good. Everything is fine with my family too. I praise the Creator for everything!
I have worked on many interesting projects. In some projects I achieved quite good results. In some projects, not really. But it doesn’t matter, it will work out on the next approach. And if it doesn’t work out, that’s also not a problem. 🙂
What can be noted:
- I changed one main job (very good) to another (even better). I worked for 4 months. Everything looks good so far. My first article “Trending Vulnerabilities 2023” was recently posted on the Positive Technologies website. The article is mainly about what trending vulnerabilities are, why you need to highlight them and why it is difficult (why you can’t use public sources as is). I have provided statistics on types of vulnerabilities, products and product groups. The article is currently only available in Russian, but Google Translate should do the trick.
- I started playing music more. And I even started posting my music recordings on YouTube from time to time. 😊 Sitting with a ukulele and singing poems that I like is one of the most enjoyable thing for me to do. And I am quite happy with my recordings, even despite all the imperfections.
- Together with Lev and Maxim, we launched an “Information Security Spotlight” news show. I never imagined that this would happen in my life, but we have already recorded 21 episodes (including the pilot).
- I’ve made good progress on my Vulristics project: new data import and export scheme, custom data source support, improved and faster product name discovery. It has become a fully functional tool! Also, in terms of coding, I am satisfied with my Linux Patch Wednesday project and the data exporter from the telegram channel to avleonov.ru. My Map of Russian Vulnerability Management Vendors project is not related to coding, but I will also note it here.
- My Russian-language Telegram channel @avleonovrus has grown quite well! By July, it had caught up and overtaken my English-language channel @avleonovcom at 1741 subscribers. And now it’s already 3838. 🤩 Cool! Thank you for reading, liking and sharing!
What about 2024?
Besides working on current projects (primarily Vulristics), I’d also like to write some open source code to manage vulnerability remediation. Just like a process; I think it would be interesting and useful both for educational purposes and for use in organizations.
I’m also thinking about turning my educational content into a book about Vulnerability Management. So far my ideas about the book are:
- The e-book will be available on my website absolutely free of charge. As for me, selling e-books is something unethical and stupid – such books will be pirated anyway. And if a book is not pirated, then this means that the book is worthless and no one needs it. Or that the author is a tireless supporter of copyright. I don’t even know which of these options is a bigger disgrace. 🙂
- The book’s sources will be available in the code repository. And there will be many editions of the book, just like there are many versions of Firefox. Perhaps a new edition will even be published every week.
- The printed book, if there is one at all, will be something like a souvenir, produced in a small circulation and inadequate, simply shamelessly expensive. An artifact and a collectible! 🙂 Accordingly, it will be printed directly, without a publisher, and will not be sold in bookstores.
But these are just my thoughts and I won’t plan or promise anything. Let it be as it will be. 🙂

Hi! My name is Alexander and I am a Vulnerability Management specialist. You can read more about me here. Currently, the best way to follow me is my Telegram channel @avleonovcom. I update it more often than this site. If you haven’t used Telegram yet, give it a try. It’s great. You can discuss my posts or ask questions at @avleonovchat.
А всех русскоязычных я приглашаю в ещё один телеграмм канал @avleonovrus, первым делом теперь пишу туда.
Pingback: После продолжительного перерыва выпустил англоязычную видяшку и блогопост | Александр В. Леонов