Masking Vulnerability Scan reports. Continuing the series of posts about Kenna (“Analyzing Vulnerability Scan data“, “Connectors and REST API“) and similar services. Is it actually safe to send your vulnerability data to some external cloud service for analysis? Leakage of such information can potentially cause great damage to your organization, right?
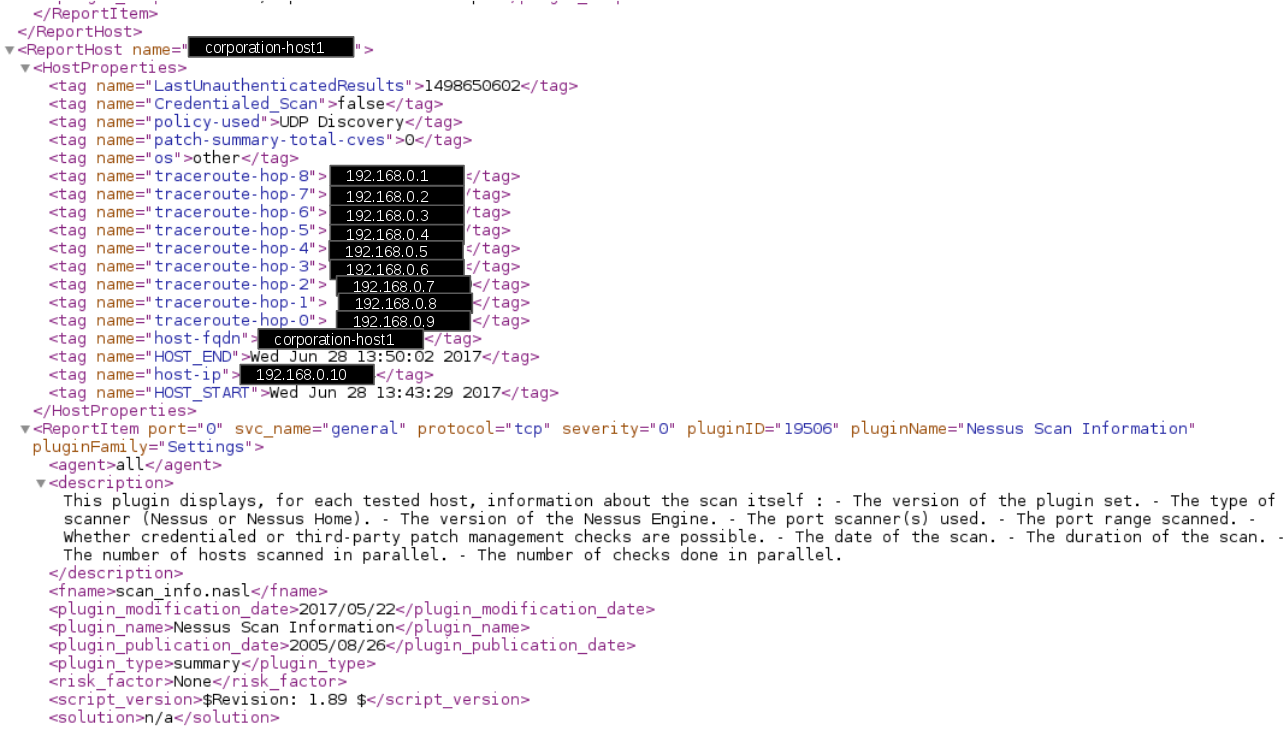
It’s once again a problem of trust to vendor. IMHO, in some cases it may make sense to hide the real hostnames and ip-addresses of the target hosts in scan reports. So, it would be clear for analysis vendor that some critical vulnerability exists somewhere, but it would not be clear where exactly.
To do this, each hostname/ip-address should be replaced to some values of similar type and should be replaced on the same value each time. So the algorithms of Kenna-like service could work with this masked reports. This mean that we need to create a replacement dictionary.