Converting Nmap xml scan reports to json. Unfortunately, Nmap can not save the results in json. All available output options:
-oN <filespec> (normal output)
-oX <filespec> (XML output)
-oS <filespec> (ScRipT KIdd|3 oUTpuT)
-oG <filespec> (grepable output)
-oA <basename> (Output to all formats)
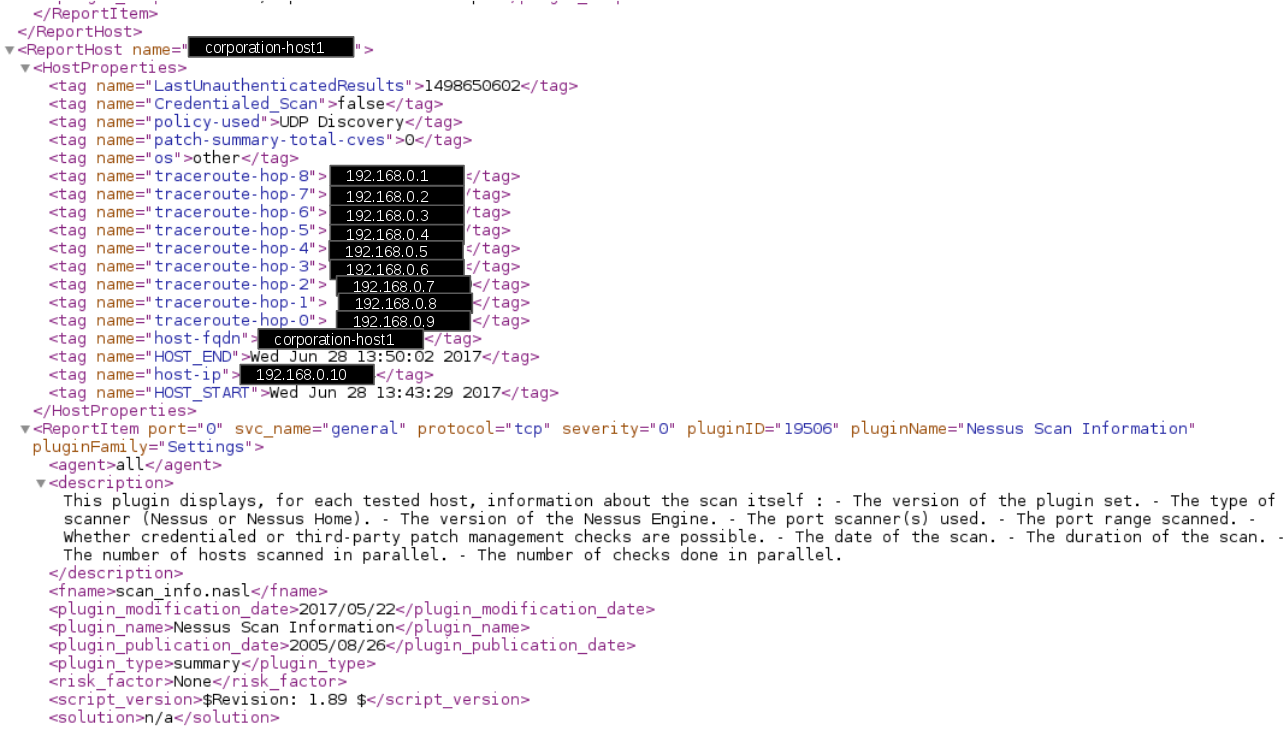
And processing xml results may not be easy an easy task. Just look how I analyze the contents of the Nessus report in “Parsing Nessus v2 XML reports with python“. Not the most readable code, right? And what alternatives do we have?

Formal XML to json conversion is impossible. Formats are very different. However, there are python modules, for example xmltodict, that can reliably convert XML into Python structures of dictionaries, lists and strings. However, they have to change some names of parameters to avoid collisions. In my opinion this is not a big price for convenience.
So, let’s see how this will work for Nmap command:
nmap -sV -oX nmap_output.xml avleonov.com 1>/dev/null 2>/dev/null